|
I am a Research Scientist at Google DeepMind in London, currently leading a team to unlock self-aligning and self-improving LLMs. For the last four years, I have led several large research projects focused on LLMs, human-AI interaction, and reinforcement learning. Before joining Google DeepMind, I completed my PhD in Machine Learning at Oxford University (advised by Stephen Roberts), interned at DeepMind with Thore Grapel, and rowed in a few countries. If you have any questions about being a researcher, engineer, or intern at DeepMind (or generally), feel free to reach out! |

|
|
I am broadly interested in leveraging LLMs to improve LLMs with minimal human data (and ideally none!). Safely unlocking this capability would allow us to scalably train, align, and evaluate increasingly capable models across a range of capabilities. For example, through automatically red-teaming for harmful behaviour, developing helpful and harmless reward models, and training populations of language models. Here are a few of my favourite papers: |

|
Cultural General Intelligence Team Richard Everett*, Edward Hughes* arxiv, 2022 arxiv | microsite | author notes | twitter We use deep reinforcement learning to generate artificial agents capable of test-time cultural transmission. Once trained, our agents can infer and recall navigational knowledge demonstrated by experts. This knowledge transfer happens in real time and generalises across a vast space of previously unseen tasks. This paves the way for cultural evolution as an algorithm for developing more generally intelligent artificial agents. |
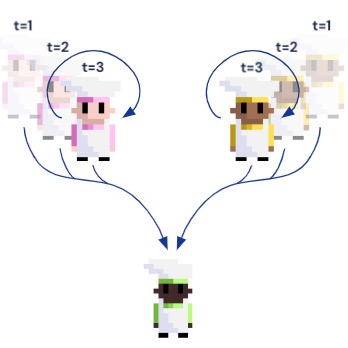
|
DJ Strouse*, Kevin R. McKee, Matt Botvinick, Edward Hughes, Richard Everett* Neural Information Processing Systems (NeurIPS), 2021 arxiv | neurips | openreview | alignment newsletter | show bibtex We introduce Fictitious Co-Play (FCP), a simple and intuitive training method for producing agents capable of zero-shot coordination with humans in Overcooked. FCP works by training an agent as the best response to a frozen pool of self-play agents and their past checkpoints. Notably, FCP exhibits robust generalization to humans, despite not using any human data during training.
@inproceedings{strouse2021fcp, |
|
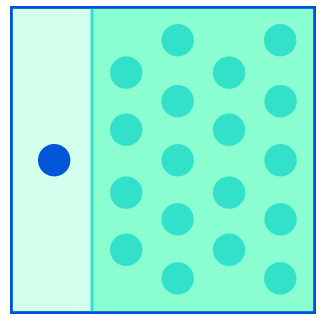
Laura Weidinger, Kevin R. McKee, Richard Everett, Saffron Huang, Tina O. Zhu, Martin J. Chadwick, Christopher Summerfield, Iason Gabriel Proceedings of the National Academy of Sciences (PNAS), 2023 PNAS | author notes The growing integration of Artificial Intelligence (AI) into society raises a critical question: How can principles be fairly selected to govern these systems? Across five studies, with a total of 2,508 participants, we use the Veil of Ignorance to select principles to align AI systems. Compared to participants who know their position, participants behind the veil more frequently choose, and endorse upon reflection, principles for AI that prioritize the worst-off. Our findings suggest that the Veil of Ignorance may be a suitable process for selecting principles to govern real-world applications of AI. |
| |